
ConcurrentHashMap 간단하게 만들어보자
모든 소스코드는 이곳에서 확인 가능합니다!
ConcurrentHashMap 간단하게 만들어보자
동시성 문제 및 일관성을 위해 Key Value 구조로 사용할 때 가장 쉽게 사용하는 것이 CoucurrentHashMap 이였지만 부끄럽게도 항상 내부구조를 보고 이렇게 동시성을 보장하는 거구나라고 생각만 하고 매번 넘겼었는데 이번 기회에 정리하고 한 번 슥-삭 만들어 보려고 합니다. 그래서 결정한 제목은 간단하게 ConcurrentHashMap 간단하게 만들어보자
ConcurrentHashMap
뭐 여타 다른 말을 생략하고 ConcurrentHashMap 말고도 여러 Map의 구현체들이 있는데, 왜 필요로 했을까를 먼저 생각해본다면 크게 2가지 정도가 있을 거 같은데요.
우리가 자주 사용하는
HashMap은 thread-safe 하지 않은 java collection입니다.Hashtable은 thread-safe하나 synchronized method 레벨에 사용을하여 비용이 매우 비쌉니다.- 즉 다시 말해 비용이 많이드는 이유는 Race condition(경쟁상태)이 발생할 수 있는 code block을 synchronized 키워드로 감싸면, 하나의 스레드만 이 진입할 수 있는데,
HashTable은 메소드 레벨에서 synchronized를 걸어버려서 다른 스레드가 먼저 진입한 스레드가 이 code block을 나갈 때까지 계속 기다려야 해서 비용적으로 매우 비싼 Collection입니다.
// 해시테이블의 put
public synchronized V put(K key, V value) {
...
}- 즉 다시 말해 비용이 많이드는 이유는 Race condition(경쟁상태)이 발생할 수 있는 code block을 synchronized 키워드로 감싸면, 하나의 스레드만 이 진입할 수 있는데,
이러한 이유로 멀티 스레드 환경에서의 map이 필요해졌는데 성능까지 신경 써야 하는 문제가 있어서 등장한 것이 동시성 성능까지 챙기게 되는 ConcurrentHashMap입니다. 참고로 자바 1.5버전부터 들어오게 되었습니다.
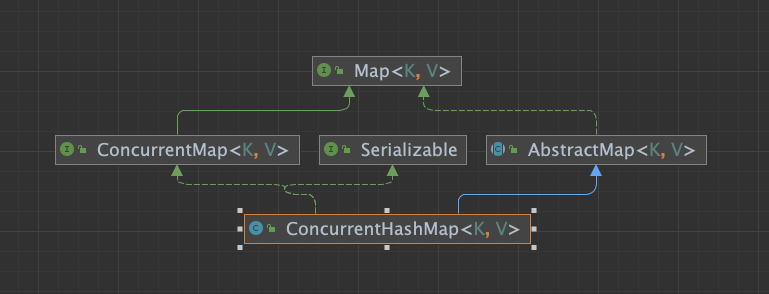
💡ConcurrentHashMap은 ConcurrentMap을 구현한 해쉬맵입니다.
ConcurrentMap
ConcurrentMap은 멀티스레딩 환경에서 키/값 작업에 대한 메모리 일관성을 보장하는 java.util.concurrent의 패키지에 있고 구현체로는 ConcurrentSkipListMap, ConcurrentSkipListMap 두 개가 있습니다.
import java.util.concurrent;
public interface ConcurrentMap<K,V> extends Map<K,V> {
...
}
그렇다면 어떻게 동시성을 보장할까?
사실 동시성을 보장하는 방법 중 가장 쉽게는 synchronized를 쓰면 안전하게 동시성을 보장할 수 있지만 쓰기에 따라서 성능 이슈가 있습니다. 특히 위에서 한 번 얘기 했지만, HashTable 에서 얘기됐던 성능이 가장 큰 문제가 있습니다. 이를 ConcurrentHashMap은 정말 멋지고 어-썸한 여러가지 방법으로 개-선을 했는데 크게 두 가지 방법들로 해결합니다.
final V putVal(K key, V value, boolean onlyIfAbsent) {
int hash = spread(key.hashCode());
...
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { --1
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value))) --2
break; // no lock when adding to empty bin
}
...새로운 Node를 삽입하기 위해,
tabAt()을 통해 해당 bucket을 가져오고bucket == null로 비어 있는지 확인한다.bucket이 비어 있을 경우 casTabAt을 통해 node를 새로 생성하는데 생성에 실패시에 다시 재시도 한다.
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectAcquire(tab, ((long)i << ASHIFT) + ABASE);
}
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSetObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
private static final Unsafe U = Unsafe.getUnsafe();
- Unsafe 메모리 접근에 관련된 함수
이미 버킷에 노드가 존재한다면 버킷별로 synchronized 사용합니다.
final V putVal(K key, V value, boolean onlyIfAbsent) {
int hash = spread(key.hashCode());
...
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
...
간단한 성능테스트
그렇다면 정말 성능에서 많은 차이가 날까? get과 put에 대한 간단한 벤치마크를 작성하면서 Hashtable, concurrentHashMap와 성능을 비교해보겠습니다.
간단하게 5개 스레드를 만들고 1,000,000 개 정도 데이터를 넣고 get을 하는 행위를 통해서 비교를 해보면
private static final Map<Integer, Integer> testHashTable = new Hashtable<>();
private static final Map<Integer, Integer> testConcurrentHashMap = new ConcurrentHashMap<>();
@Test
void test() throws Exception {
long hashTableAvgTime = measure_GetPut(testHashTable);
long concurrentHashMapAvgTime = measure_GetPut(testConcurrentHashMap);
System.out.println("hashTableAvgTime = " + hashTableAvgTime);
System.out.println("concurrentHashMapAvgTime = " + concurrentHashMapAvgTime);
}
private static long measure_GetPut(Map<Integer, Integer> map) throws InterruptedException {
ExecutorService executor = Executors.newFixedThreadPool(4);
long startTime = System.nanoTime();
for (int i = 0; i < 5; i++) {
executor.submit(() -> {
for (int j = 0; j < 1_000_000; j++) {
int value = ThreadLocalRandom
.current()
.nextInt(100_000);
map.put(value, value);
map.get(value);
}
});
}
executor.shutdown();
if (executor.awaitTermination(30, TimeUnit.SECONDS)) {
System.out.println(map.getClass());
} else {
executor.shutdownNow();
}
long endTime = System.nanoTime();
return (endTime - startTime) / 5_000_000;
}
잘 정리된 사이트가 있어서 올리지만 요약하자면 Random은 멀티 스레드에서 하나의 Random 인스턴스를 공유하여 전역적으로 동작해서 선형 합동 생성기 알고리즘을 사용하는 반면 ThreadLocalRandom 각 스레드마다 다른 인스턴스를 생성합니다.
https://velog.io/@sojukang/Random-대신-ThreadLocalRandom을-써야-하는-이유
참고로 환경은 m1book Pro, 16GB에서 테스트 해보았습니다.
대략 10번 정도의 테스트 후에 나온 결과 값입니다.
hashTableAvgTime = 1228
concurrentHashMapAvgTime = 317
확실히, 메소드 레벨에서 락을 거는 방법으로 put을 처리하는 hashtable과 달리 ConcurrentHashMap은 버킷당으로 lock을 걸고 cas 알고리즘을 사용하는등을 통한 여러 기법들로 성능상 상승이 나타난 걸로 보입니다.
길었는데 만들어보는 건 다음 2편에서:)
참고
https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/ConcurrentMap.html
https://www.baeldung.com/java-concurrent-map
https://www.programiz.com/java-programming/concurrenthashmap
https://www.geeksforgeeks.org/concurrenthashmap-in-java/
https://bcho.tistory.com/1072
https://en.wikipedia.org/wiki/Hash_table
https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/ConcurrentHashMap.html
CAS
https://d2.naver.com/helloworld/831311
https://velog.io/@sojukang/Random-대신-ThreadLocalRandom을-써야-하는-이유